Optimizations Behind Performance
Early versions of Apache Doris focused on online analytical processing (OLAP), primarily for reporting and aggregation workloads—typical queries being multi-table JOIN and GROUP BY. In 2.x, Doris added text search via inverted indexes and introduced the Variant type for efficient JSON handling. In 3.x, storage-compute separation enabled leveraging object storage to significantly reduce storage costs. In 4.x, Doris steps into the AI era by introducing vector indexes and hybrid search (vector + text), positioning Doris as an enterprise AI analytics platform. This document explains how Doris implements vector indexing in 4.x and the engineering efforts made to reach state-of-the-art performance.
We divide vector indexing into two stages: indexing and querying. The indexing stage focuses on 1) data sharding, 2) efficiently building high-quality indexes, and 3) index management. The querying stage has a single goal: improve query performance—eliminating redundant computation and unnecessary IO while optimizing concurrency.
Indexing Stage
Indexing performance is strongly tied to index hyperparameters: higher index quality typically means longer build time. Thanks to optimizations in the ingestion path, Doris can maintain high index quality while improving ingestion throughput.
On the 768D 10M dataset, Apache Doris achieves industry-leading ingestion performance.
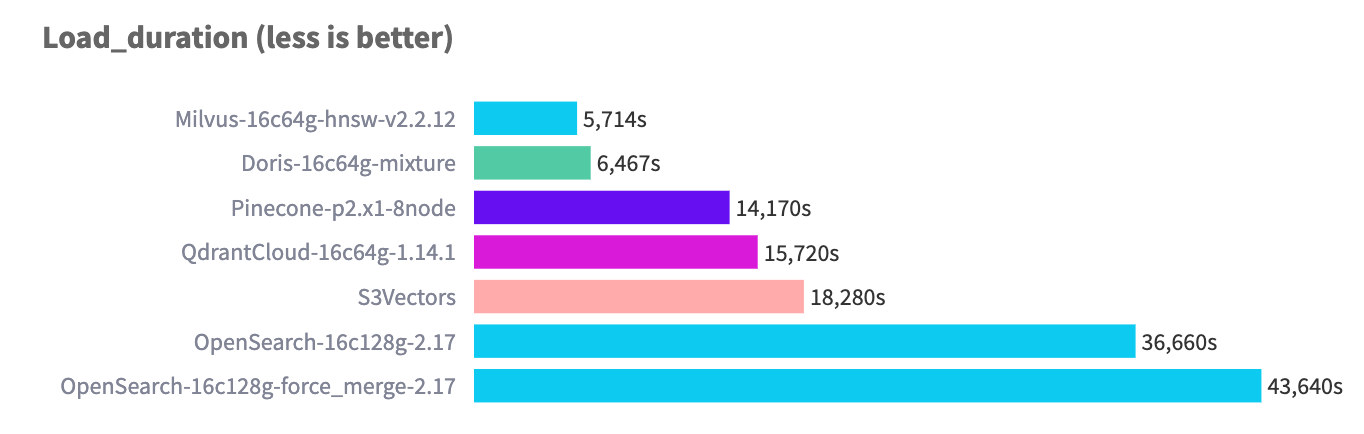
Multi-Level Sharding
Internal tables in Apache Doris are inherently distributed. During query and ingestion, users interact with a single logical table, while the Doris kernel creates the required number of physical tablets based on the table definition. During ingestion, data is routed to the appropriate BE tablet by partition and bucket keys. Multiple tablets together form the logical table seen by users. Each ingestion request forms a transaction, creating a rowset (versioning unit) on the corresponding tablet. Each rowset contains several segments, and the segment is the actual data carrier; ANN indexes operate at the segment granularity.
Vector indexes (e.g., HNSW) rely on key hyperparameters that directly determine index quality and query performance, and are typically tuned for specific data scales. Apache Doris’s multi-level sharding decouples “index parameters” from the “full table data scale”: users need not rebuild indexes as total data grows, but only tune parameters based on per-batch ingestion size. From our tests, HNSW suggested parameters under different batch sizes are:
| batch_size | max_degree | ef_construction | ef_search | recall@100 |
|---|---|---|---|---|
| 250000 | 100 | 200 | 50 | 89% |
| 250000 | 100 | 200 | 100 | 93% |
| 250000 | 100 | 200 | 150 | 95% |
| 250000 | 100 | 200 | 200 | 98% |
| 500000 | 120 | 240 | 50 | 91% |
| 500000 | 120 | 240 | 100 | 94% |
| 500000 | 120 | 240 | 150 | 96% |
| 500000 | 120 | 240 | 200 | 99% |
| 1000000 | 150 | 300 | 50 | 90% |
| 1000000 | 150 | 300 | 100 | 93% |
| 1000000 | 150 | 300 | 150 | 96% |
| 1000000 | 150 | 300 | 200 | 98% |
In short, focus on “per-batch ingestion size” and choose proper index parameters to maintain quality and stable query behavior.
High-Performance Index Building
Parallel, High-Quality Index Construction
Doris accelerates index builds with two-level parallelism: cluster-level parallelism across BE nodes, and intra-node multithreaded distance computation on grouped batch data. Beyond speed, Doris improves index quality via in-memory batching: when the total vector count is fixed but batching is too fine (frequent incremental builds), graph structures become sparser and recall drops. For example, on 768D10M, building in 10 batches may reach ~99% recall, while 100 batches may drop to ~95%. In-memory batching balances memory usage and graph quality under the same hyperparameters, avoiding quality degradation from over-batching.
SIMD
The core cost in ANN index building is large-scale distance computation—a CPU-bound workload. Doris centralizes this work on BE nodes, implemented in C++, and leverages Faiss’s automatic and manual vectorization optimizations. For L2 distance, Faiss uses compiler pragmas to trigger auto-vectorization:
FAISS_PRAGMA_IMPRECISE_FUNCTION_BEGIN
float fvec_L2sqr(const float* x, const float* y, size_t d) {
size_t i; float res = 0;
FAISS_PRAGMA_IMPRECISE_LOOP
for (i = 0; i < d; i++) {
const float tmp = x[i] - y[i];
res += tmp * tmp;
}
return res;
}
FAISS_PRAGMA_IMPRECISE_FUNCTION_END
With FAISS_PRAGMA_IMPRECISE_*, compilers auto-vectorize:
#define FAISS_PRAGMA_IMPRECISE_LOOP \
_Pragma("clang loop vectorize(enable) interleave(enable)")
Faiss also applies explicit SIMD in #ifdef SSE3/AVX2/AVX512F blocks using _mm*/_mm256*/_mm512*, combined with ElementOpL2/ElementOpIP and dimension-specialized fvec_op_ny_D{1,2,4,8,12} to:
- Process multiple samples per iteration (e.g., 8/16) and perform register-level transpose to improve memory access locality;
- Use FMA (e.g.,
_mm512_fmadd_ps) to fuse multiply-add and reduce instruction count; - Do horizontal sums to produce scalars efficiently;
- Handle tail elements via masked reads for non-aligned sizes. These optimizations reduce instruction and memory costs and significantly boost indexing throughput.
Querying Stage
Search is latency sensitive. At tens of millions of records with high concurrency, P99 latency typically needs to be under 500 ms—raising the bar for the optimizer, execution engine, and index implementation. Out-of-the-box tests show Doris reaches performance comparable to mainstream dedicated vector databases. The chart below compares Doris against other systems on Performance768D10M; peer data comes from Zilliz’s open-source VectorDBBench.
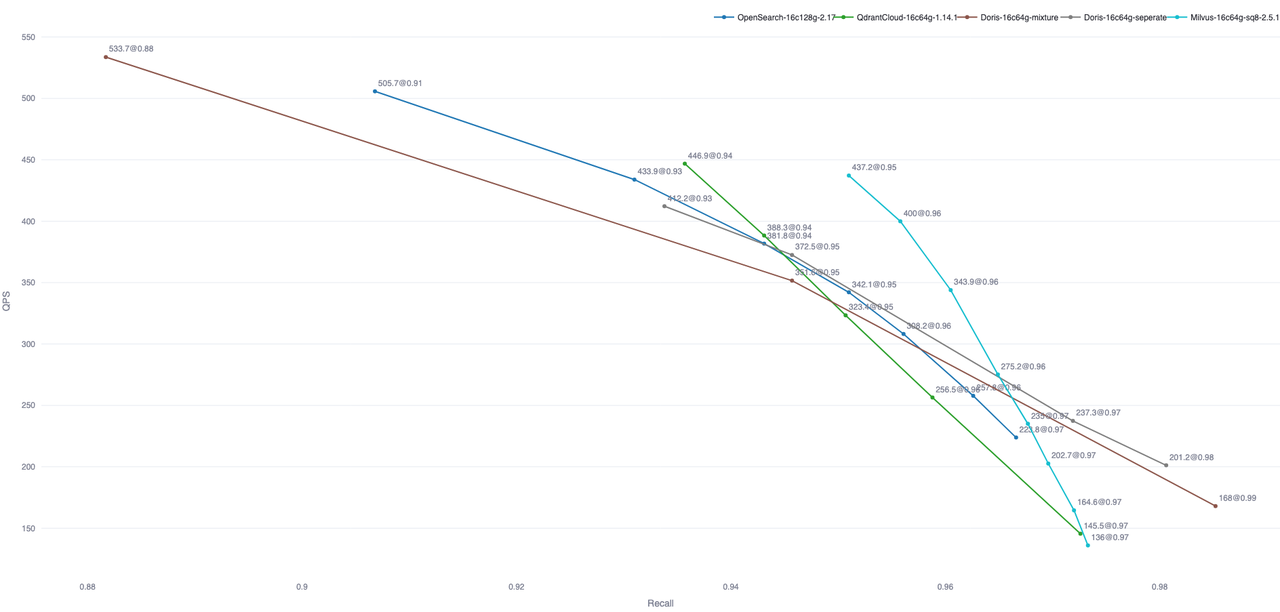
Note: The chart includes a subset of out-of-the-box results. OpenSearch and Elastic Cloud can improve query performance by optimizing the number of index files.
Prepare Statement
In the traditional path, Doris runs full optimization (parsing, semantic analysis, RBO, CBO) for every SQL. While essential for general OLAP, this adds overhead for simple, highly repetitive search queries. Doris 4.0 extends Prepare Statement beyond point lookups to all SQL types, including vector search:
- Separate compile and execute
- Prepare performs parsing, semantics, and optimization once, producing a reusable Logical Plan.
- Execute binds parameters at runtime and runs the pre-built plan, skipping the optimizer entirely.
- Plan cache
- Reuse is determined by SQL fingerprint (normalized SQL + schema version).
- Different parameter values with the same structure reuse the cached plan, avoiding re-optimization.
- Schema version check
- Validate schema version at execution to ensure correctness.
- No change → reuse; changed → invalidate and re-prepare.
- Speedup by skipping optimizer
- Execute no longer runs RBO/CBO; optimizer time is nearly eliminated.
- Template-heavy vector queries benefit with significantly lower end-to-end latency.
Index Only Scan
Doris implements vector indexes as external (pluggable) indexes, which simplifies management and supports asynchronous builds, but introduces performance challenges such as avoiding redundant computation and IO. ANN indexes can return distances in addition to row IDs. Doris leverages this by short-circuiting distance expressions within the Scan operator via “virtual columns,” and the Ann Index Only Scan fully eliminates distance-related read IO. In the naive flow, Scan pushes predicates to the index, the index returns row IDs, and Scan then reads data pages and computes expressions before returning N rows upstream.
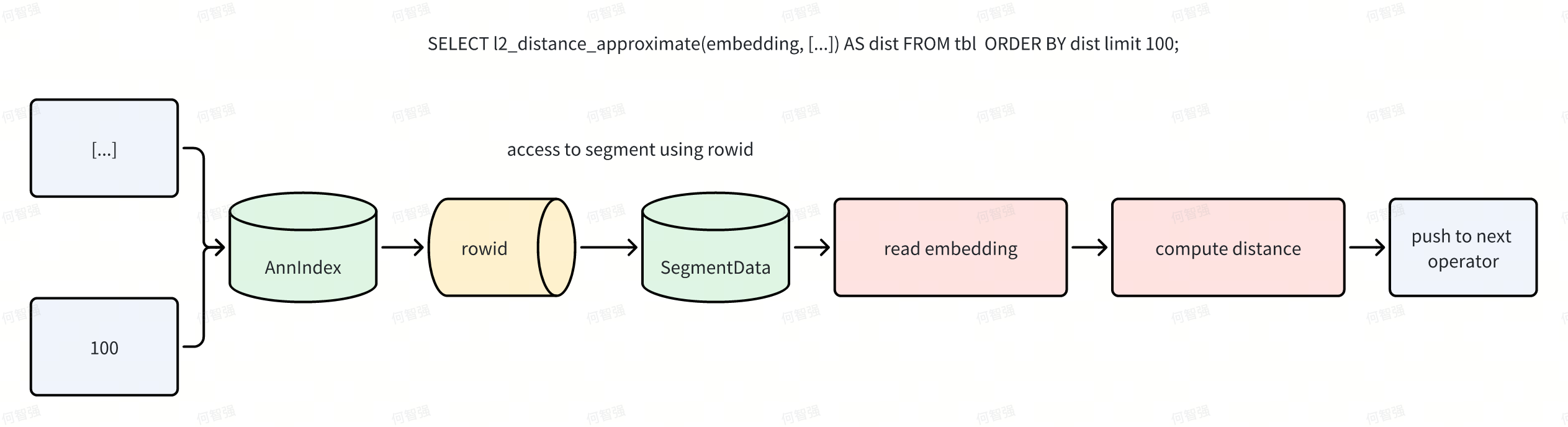
With Index Only Scan applied, the flow becomes:
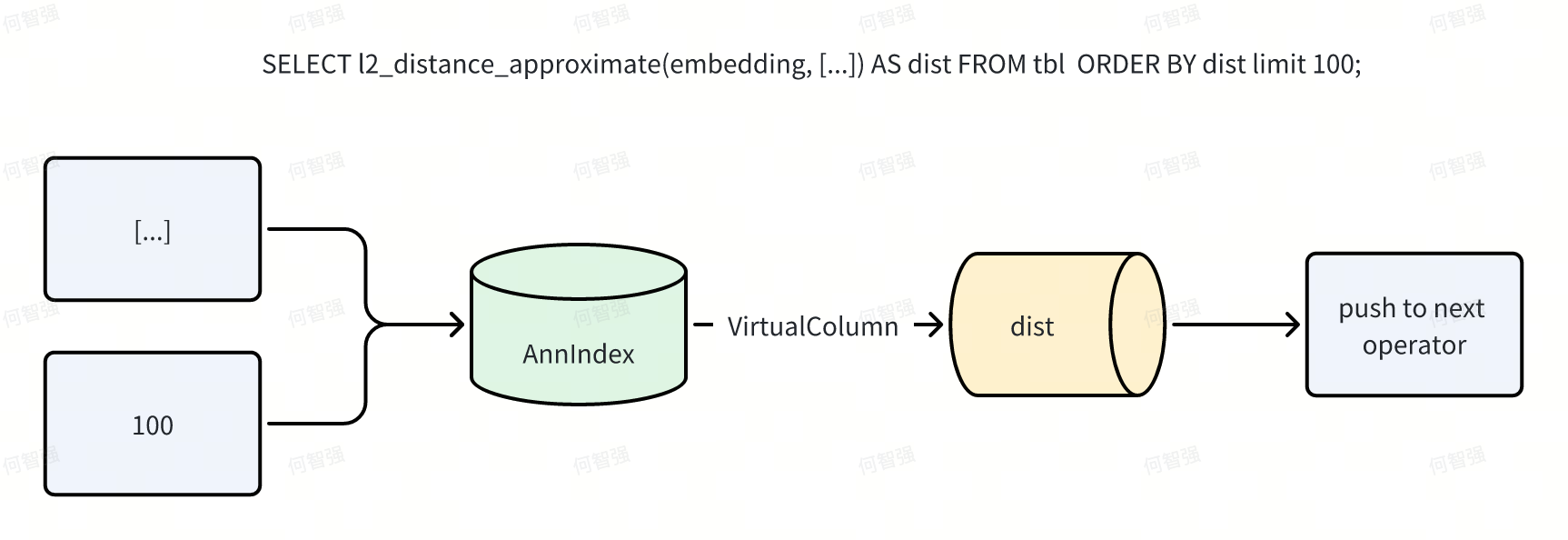
For example, SELECT l2_distance_approximate(embedding, [...]) AS dist FROM tbl ORDER BY dist LIMIT 100; executes without touching data files.
Beyond Ann TopN Search, Range Search and Compound Search adopt similar optimizations. Range Search is more nuanced: whether the index returns dist depends on the comparator. Below lists query types related to Ann Index Only Scan and whether Index Scan applies:
-- Sql1: Range + proj
-- Index returns dist; no need to recompute dist
-- Virtual column for CSE avoids dist recomputation in proj
-- IndexScan: True
select id, dist(embedding, [...]) from tbl where dist <= 10;
-- Sql2: Range + no-proj
-- Index returns dist; no need to recompute
-- IndexScan: True
select id from tbl where dist <= 10 order by id limit N;
-- Sql3: Range + proj + no-dist-from index
-- Index cannot return dist (only updates rowid map)
-- proj requires dist → embedding must be reread
-- IndexScan: False
select id, dist(embedding, [...]) from tbl where dist > 10;
-- Sql4: Range + proj + no-dist-from index
-- Index cannot return dist, but proj does not need dist → embedding not reread
-- IndexScan: True
select id from tbl where dist > 10;
-- Sql5: TopN
-- Index returns dist; virtual slot for CSE uploads dist to proj
-- embedding column not read
-- IndexScan: True
select id[, dist(embedding, [...])] from tbl order by dist(embedding, [...]) asc limit N;
-- Sql6: TopN + IndexFilter
-- 1) comment not read (inverted index already optimizes this)
-- 2) embedding not read (same reason as Sql5)
-- IndexScan: True
select id[, dist(embedding, [...])] from tbl where comment match_any 'olap' ORDER BY dist(embedding, [...]) LIMIT N;
-- Sql7: TopN + Range
-- IndexScan: True (combination of Sql1 and Sql5)
select id[, dist(embedding, [...])] from tbl where dist(embedding, [...]) > 10 order by dist(embedding, [...]) limit N;
-- Sql8: TopN + Range + IndexFilter
-- IndexScan: True (combination of Sql7 and Sql6)
select id[, dist(embedding, [...])] from tbl where comment match_any 'olap' and dist(embedding, [...]) > 10 ORDER BY dist(embedding, [...]) LIMIT N;
-- Sql9: TopN + Range + CommonFilter
-- Key points: 1) dist < 10 (not > 10); 2) common filter reads dist, not embedding
-- Index returns dist; virtual slot for CSE ensures all reads refer to the same column
-- In theory embedding need not materialize; in practice it still does due to residual predicates on the column
-- IndexScan: False
select id[, dist(embedding, [...])] from tbl where comment match_any 'olap' and dist(embedding, [...]) < 10 AND abs(dist(embedding) + 10) > 10 ORDER BY dist(embedding, [...]) LIMIT N;
-- Sql10: Variant of Sql9, dist < 10 → dist > 10
-- Index cannot return embedding; to compute abs(dist(embedding,...)) embedding must materialize
-- IndexScan: False
select id[, dist(embedding, [...])] from tbl where comment match_any 'olap' and dist(embedding, [...]) > 10 AND abs(dist(embedding) + 10) > 10 ORDER BY dist(embedding, [...]) LIMIT N;
-- Sql11: Variant of Sql9, abs(dist(...)+10) > 10 → array_size(embedding) > 10
-- array_size requires embedding materialization
-- IndexScan: False
select id[, dist(embedding, [...])] from tbl where comment match_any 'olap' and dist(embedding, [...]) < 10 AND array_size(embedding) > 10 ORDER BY dist(embedding, [...]) LIMIT N;
Virtual Columns for CSE
Index Only Scan mainly eliminates IO (random reads of embedding). To further remove redundant computation, Doris introduces virtual columns that pass index-returned dist into the expression engine as a column.
Design highlights:
- Expression node
VirtualSlotRef - Column iterator
VirtualColumnIterator
VirtualSlotRef is a compute-time-generated column: materialized by one expression, reusable by many, computed once on first use—eliminating CSE across Projection and predicates. VirtualColumnIterator materializes index-returned distances into expressions, avoiding repeated distance calculations. Initially built for ANN query CSE elimination, the mechanism was generalized to Projection + Scan + Filter.
Using the ClickBench dataset, the query below counts the top 20 websites by Google clicks:
set experimental_enable_virtual_slot_for_cse=true;
SELECT counterid,
COUNT(*) AS hit_count,
COUNT(DISTINCT userid) AS unique_users
FROM hits
WHERE ( UPPER(regexp_extract(referer, '^https?://([^/]+)', 1)) = 'GOOGLE.COM'
OR UPPER(regexp_extract(referer, '^https?://([^/]+)', 1)) = 'GOOGLE.RU'
OR UPPER(regexp_extract(referer, '^https?://([^/]+)', 1)) LIKE '%GOOGLE%' )
AND ( LENGTH(regexp_extract(referer, '^https?://([^/]+)', 1)) > 3
OR regexp_extract(referer, '^https?://([^/]+)', 1) != ''
OR regexp_extract(referer, '^https?://([^/]+)', 1) IS NOT NULL )
AND eventdate = '2013-07-15'
GROUP BY counterid
HAVING hit_count > 100
ORDER BY hit_count DESC
LIMIT 20;
The core expression regexp_extract(referer, '^https?://([^/]+)', 1) is CPU-intensive and reused across predicates. With virtual columns enabled (set experimental_enable_virtual_slot_for_cse=true;):
- Enabled: 0.57 s
- Disabled: 1.50 s
End-to-end performance improves by ~3x.
Scan Parallelism Optimization
Doris revamped Scan parallelism for Ann TopN Search. The original policy set parallelism by row count (default: 2,097,152 rows per Scan Task). Because segments are size-based, high-dimensional vector columns produce far fewer rows per segment, leading to multiple segments being scanned serially within one Scan Task. Doris switched to “one Scan Task per segment,” boosting parallelism in index scanning; given Ann TopN’s high filter rate (only N rows returned), the back-to-table phase can remain single-threaded without hurting performance. On SIFT 1M:
set optimize_index_scan_parallelism=true;
TopN single-threaded query latency drops from 230 ms to 50 ms.
Additionally, 4.0 introduces dynamic parallelism: before each scheduling round, Doris adjusts the number of submitted Scan tasks based on thread-pool pressure—reducing tasks under high load, increasing when idle—to balance resource use and scheduling overhead across serial and concurrent workloads.
Global TopN Delayed Materialization
A typical Ann TopN query executes in two stages:
- Scan obtains per-segment TopN distances via the index;
- Global sort merges per-segment TopN to produce the final TopN.
If the projection returns many columns or large types (e.g., String), stage-1 reading N rows from each segment can incur heavy IO—and many rows are discarded during stage-2 global sort. Doris minimizes stage-1 IO via global TopN delayed materialization.
For SELECT id, l2_distance_approximate(embedding, [...]) AS dist FROM tbl ORDER BY dist LIMIT 100;: stage-1 outputs only 100 dist values and rowids per segment via Ann Index Only Scan + virtual columns. With M segments, stage-2 globally sorts 100 * M dist values to obtain the final TopN and rowids, then the Materialize operator fetches the needed columns by rowid from corresponding tablet/rowset/segment.